MiniMax explica por qué su modelo M2 ‘olvidó’ un nombre: deriva de tokens en el post-entrenamiento
MiniMax ha publicado un informe técnico detallado explicando por qué su modelo M2 no logró generar correctamente un nombre chino específico, atribuyendo el problema a la degradación de tokens de baja frecuencia durante el post-entrenamiento. El incidente destaca un desafío más amplio de fiabilidad en los modelos de lenguaje de gran tamaño: una cobertura desigual de tokens puede provocar una deriva estructural en el espacio de embeddings, afectando nombres, idiomas extranjeros y símbolos poco com
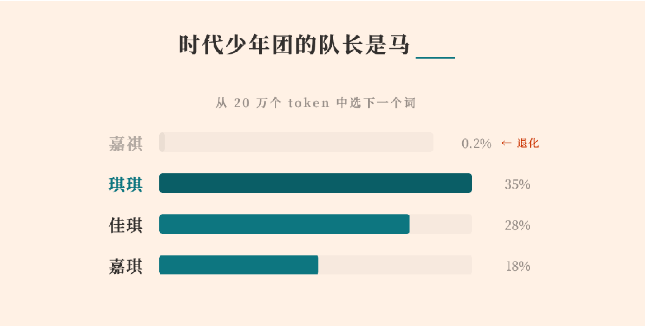
MiniMax ha publicado un informe técnico detallado explicando por qué su modelo de lenguaje de gran tamaño de la serie M2 no pudo generar correctamente un nombre chino específico, “马嘉祺.” Lo que inicialmente parecía un fallo aislado de salida se ha convertido en un revelador estudio de caso sobre cómo las dinámicas posteriores al entrenamiento pueden degradar silenciosamente los tokens de baja frecuencia en los modelos de lenguaje de gran tamaño (LLMs).
La causa raíz: un token “comprimido”
Según MiniMax, el problema se originó en el tokenizador del modelo. El nombre “马嘉祺” se dividió en dos tokens: “马” y “嘉祺.” Durante el preentrenamiento, “嘉祺” apareció con suficiente frecuencia en datos a escala web como para fusionarse en un token independiente (ID 190467). El modelo aprendió su representación como se esperaba.
Sin embargo, en la fase posterior de entrenamiento—donde se realizan el ajuste por instrucciones y la optimización del diálogo—el token “嘉祺” apareció menos de cinco veces en el conjunto de datos curado para el ajuste fino. Mientras tanto, tokens de alta frecuencia relacionados con la sintaxis de código, marcadores de invocación de herramientas y patrones conversacionales comunes fueron reforzados repetidamente.
Como resultado, la incrustación del token de baja frecuencia casi no recibió actualizaciones de gradiente, mientras que los tokens vecinos de alta frecuencia continuaron desplazándose en el espacio vectorial. Con el tiempo, esto condujo a lo que MiniMax describe como “deriva” o “degeneración” del token. El modelo aún conservaba conocimiento sobre la persona, pero perdió la capacidad de generar de forma fiable el token correcto, produciendo en su lugar alternativas fonéticamente similares.
Un patrón más amplio: lenguaje y degradación de tokens de cola larga
MiniMax realizó un análisis de aproximadamente 200.000 tokens del vocabulario y descubrió que alrededor del 4,9% mostraba una degradación significativa después del post-entrenamiento. El problema fue particularmente agudo en los tokens japoneses, que presentaron una tasa de degradación del 29,7%.
Esto ayuda a explicar anomalías observadas previamente, como respuestas en japonés que ocasionalmente mezclaban caracteres rusos o coreanos. Cuando ciertos tokens de un idioma están subrepresentados durante el ajuste fino, sus incrustaciones pueden derivar hacia regiones cercanas en el espacio vectorial, causando confusión entre idiomas.
La degradación también afectó a símbolos LaTeX, marcado de Wikipedia y palabras clave SEO de baja calidad que rara vez aparecen en los conjuntos de datos de ajuste por instrucciones. En esencia, cualquier token que careciera de exposición suficiente durante el post-entrenamiento corría el riesgo de ser “desplazado” por tokens actualizados con mayor frecuencia.
Por qué el post-entrenamiento crea un riesgo estructural
El caso subraya una tensión estructural en el desarrollo de LLMs. Los tokenizadores suelen construirse a partir de grandes corpus de preentrenamiento diversos. Pero los conjuntos de datos de post-entrenamiento—optimizados para utilidad, seguridad y calidad del diálogo—son mucho más estrechos en su distribución. Cuando la cobertura entre tokens se vuelve desigual, los desequilibrios estadísticos pueden acumularse a nivel de incrustación.
Aunque el razonamiento de alto nivel y la capacidad conversacional del modelo puedan mejorar, su estabilidad léxica de bajo nivel puede erosionarse silenciosamente. El incidente de MiniMax demuestra que los desafíos de fiabilidad pueden surgir no por lagunas de conocimiento, sino por deriva representacional a nivel de token.
Estrategia de mitigación de MiniMax
Para abordar el problema, MiniMax implementó tres medidas correctivas:
- Cobertura sintética de vocabulario completo: El equipo generó tareas sintéticas del tipo “repite después de mí” para asegurar que cada token del vocabulario reciba una frecuencia mínima de actualizaciones durante el post-entrenamiento.
- Mezcla de datos de preentrenamiento: Se incorporaron partes del corpus original de amplia cobertura en la etapa de ajuste fino supervisado para contrarrestar el olvido.
- Depuración y monitoreo del vocabulario: Los tokens raramente utilizados u obsoletos pueden eliminarse, y las métricas de cobertura de tokens ahora se incluyen en los controles de calidad del post-entrenamiento.
Tras estas correcciones, MiniMax informa que la confusión entre idiomas en las salidas en japonés se redujo del 47% al 1%, y que la estabilidad general de los tokens mejoró en todo el vocabulario.
Implicaciones para la industria
Este episodio pone de relieve un problema de fiabilidad poco discutido en los modelos de lenguaje de gran tamaño: la cobertura a nivel de token durante el post-entrenamiento. A medida que los modelos se especializan cada vez más mediante ajuste por instrucciones y aprendizaje por refuerzo, mantener el equilibrio estadístico entre cientos de miles de tokens se convierte en un desafío de ingeniería nada trivial.
Para los desarrolladores de IA, la conclusión es clara: mejorar la alineación semántica y el rendimiento en tareas no puede hacerse a expensas de la estabilidad léxica. Las métricas de cobertura de tokens, la detección de deriva de incrustaciones y las estrategias equilibradas de ajuste fino pueden convertirse en componentes críticos de los futuros procesos de evaluación de modelos.
Lo que comenzó como un modelo “olvidando” un nombre revela en última instancia una verdad más profunda sobre las dinámicas de entrenamiento de los LLM: en espacios vectoriales de alta dimensión, descuidar la cola larga puede remodelar silenciosamente los cimientos del sistema.