OpenAI publikuje benchmark GeneBench-Pro, zwiększając możliwości analizy biologicznej modeli AI
OpenAI zaprezentowało nowy benchmark GeneBench-Pro, służący do oceny rzeczywistych zdolności badawczych AI w złożonych zadaniach biologicznych, takich jak genomika i proteomika. W przeciwieństwie do tradycyjnych testów, które kładą nacisk na pamięć i stałe procedury, ten benchmark bardziej koncentruje się na ocenie, analizie i podejmowaniu decyzji przez modele w chaotycznym środowisku niekompletnych danych.

W obliczu szybkiego rozwoju biotechnologii, skuteczna i precyzyjna analiza złożonych danych biologicznych stała się jednym z kluczowych wyzwań stojących przed badaczami. Aby zwiększyć rzeczywiste możliwości analityczne AI w tej dziedzinie, OpenAI niedawno zaprezentowało nowy benchmark GeneBench-Pro, który koncentruje się na ocenie zdolności modeli badawczych w zadaniach z zakresu genomiki, proteomiki i pokrewnych obszarów, ze szczególnym uwzględnieniem jakości osądu i podejmowania decyzji w obliczu chaotycznych i niekompletnych danych.
Kluczowe różnice względem tradycyjnych benchmarków
GeneBench-Pro wyraźnie różni się od tradycyjnych benchmarków. Klasyczne testy zwykle kładą większy nacisk na pamięć modelu oraz na to, czy potrafi on wykonać zadanie zgodnie z ustalonym schematem; GeneBench-Pro mocniej akcentuje natomiast praktyczną użyteczność modelu w rzeczywistym środowisku naukowym.
Na poziomie projektowania zadań benchmark celowo wprowadza środowisko danych „niejednoznacznych, niekompletnych i obciążonych zakłóceniami”, wymagając od modelu prowadzenia eksploracji i analizy danych w złożonych warunkach, aby bardziej realistycznie odzwierciedlić jego zdolność do formułowania ocen badawczych.
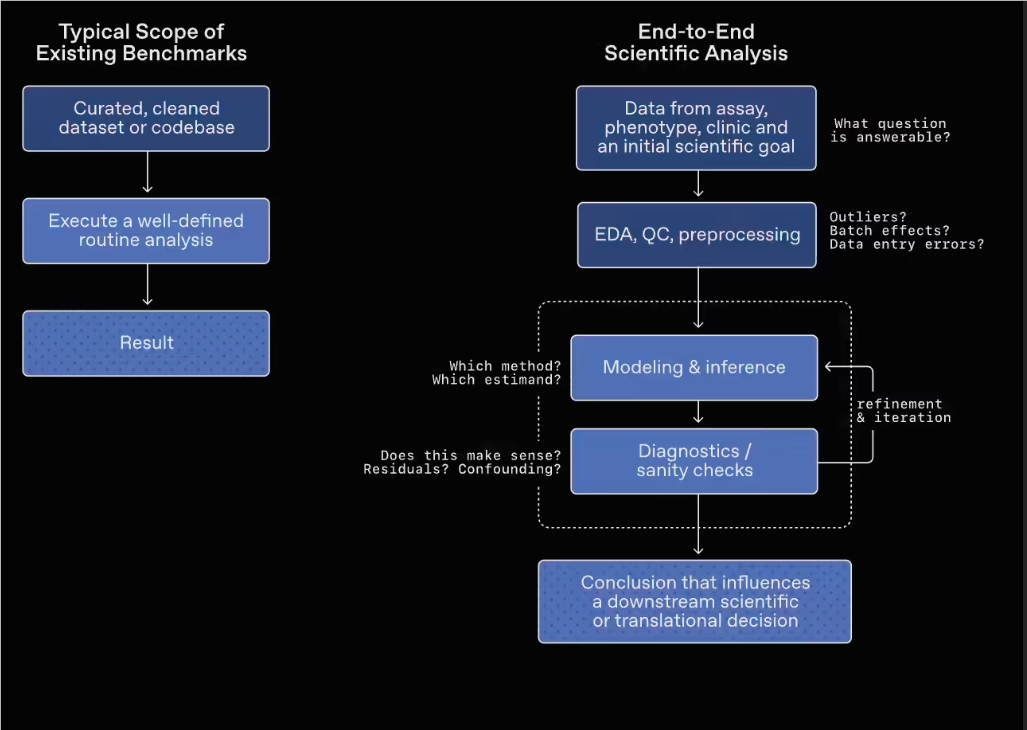
Zakres dziedzin i konstrukcja zadań
GeneBench-Pro obejmuje wiele kierunków biologii, w tym genomikę, biologię ilościową i medycynę translacyjną, i zawiera łącznie 129 zadań z różnych subdyscyplin:
- genetyka statystyczna
- genetyka populacyjna
- genomika funkcjonalna
- proteomika
W ramach testu każde zadanie dostarcza modelowi zbiór danych zbliżony do realnych warunków pracy badawczej, wraz z krótkim opisem tła eksperymentalnego i samego problemu. Model musi samodzielnie wybrać metodę analizy, a następnie dynamicznie korygować strategię w trakcie pracy analitycznej, by ostatecznie sformułować wniosek.
Wykorzystanie danych syntetycznych w celu ograniczenia błędów oceny
Aby ograniczyć błędy oceniania często spotykane w tradycyjnych, wieloetapowych testach, OpenAI zastosowało w projekcie GeneBench-Pro dane syntetyczne. Takie podejście pomaga lepiej kontrolować proces generowania danych, dzięki czemu wyniki ewaluacji lepiej odzwierciedlają rzeczywiste zdolności modelu w zakresie rozumienia i analizy, zamiast opierać się na zgadywaniu lub skrótach prowadzących do odpowiedzi.
Otwarte przykłady i dalsze plany ewaluacyjne
Obecnie OpenAI udostępniło na platformie Hugging Face 10 reprezentatywnych przykładowych zadań GeneBench-Pro, z którymi zewnętrzni badacze mogą zapoznać się poprzez interaktywny interfejs.
Ponadto OpenAI planuje przekazać 50 zadań organizacji Artificial Analysis do niezależnej oceny, aby dalej zweryfikować rzeczywiste wyniki różnych modeli w tym benchmarku.