MiniMax wyjaśnia, dlaczego jego model M2 „zapomniał” imię: dryf tokenów w treningu po wstępnym uczeniu
MiniMax opublikował techniczną analizę po incydencie, wyjaśniając, dlaczego model M2 nie wygenerował poprawnie konkretnego chińskiego imienia, wskazując na degradację tokenów o niskiej częstotliwości podczas treningu po wstępnym uczeniu. Zdarzenie to podkreśla szersze wyzwanie związane z niezawodnością dużych modeli językowych: nierównomierne pokrycie tokenów może powodować dryf strukturalny w przestrzeni osadzeń, wpływając na imiona, języki obce i rzadkie symbole.
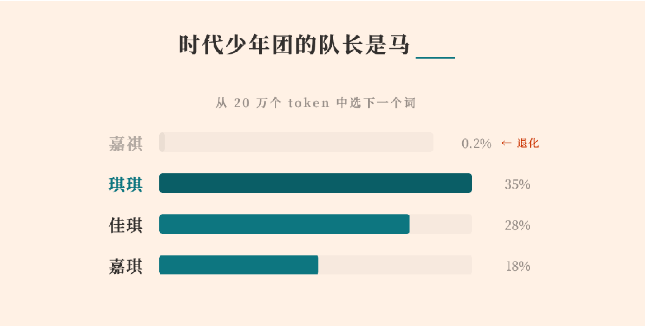
MiniMax opublikował szczegółowy raport techniczny wyjaśniający, dlaczego jego model językowy z serii M2 nie był w stanie poprawnie wygenerować konkretnego chińskiego imienia „马嘉祺”. To, co początkowo wydawało się odosobnioną usterką w generowaniu odpowiedzi, przerodziło się w pouczające studium przypadku pokazujące, jak dynamika po etapie wstępnego treningu może w sposób niezauważalny pogarszać jakość rzadko występujących tokenów w dużych modelach językowych (LLM).
Główna przyczyna: „ściśnięty” token
Według MiniMax problem miał swoje źródło w tokenizerze modelu. Imię „马嘉祺” zostało podzielone na dwa tokeny: „马” oraz „嘉祺”. Podczas wstępnego treningu „嘉祺” pojawiało się wystarczająco często w danych pochodzących z internetu, aby zostać scalone w samodzielny token (ID 190467). Model nauczył się jego reprezentacji zgodnie z oczekiwaniami.
Jednak w późniejszej fazie treningu — obejmującej dostrajanie instrukcyjne i optymalizację dialogową — token „嘉祺” pojawił się mniej niż pięć razy w wyselekcjonowanym zbiorze danych do fine-tuningu. Jednocześnie tokeny o wysokiej częstotliwości, związane ze składnią kodu, znacznikami wywołań narzędzi oraz typowymi wzorcami konwersacyjnymi, były wielokrotnie wzmacniane.
W rezultacie embedding rzadko występującego tokenu praktycznie nie otrzymywał aktualizacji gradientu, podczas gdy sąsiednie, często używane tokeny nadal przesuwały się w przestrzeni wektorowej. Z czasem doprowadziło to do zjawiska, które MiniMax określa jako „dryf” lub „degenerację” tokenu. Model wciąż zachowywał wiedzę o tej osobie, lecz utracił zdolność do niezawodnego generowania poprawnego tokenu, zamiast tego tworząc fonetycznie podobne alternatywy.
Szerszy wzorzec: degradacja językowa i długi ogon tokenów
MiniMax przeprowadził analizę około 200 000 tokenów słownika i stwierdził, że około 4,9% z nich wykazało istotną degradację po etapie post-treningu. Problem był szczególnie dotkliwy w przypadku tokenów japońskich, które odnotowały wskaźnik degradacji na poziomie 29,7%.
Wyjaśnia to wcześniej obserwowane anomalie, takie jak sporadyczne mieszanie w odpowiedziach japońskich znaków rosyjskich lub koreańskich. Gdy niektóre tokeny językowe są niedostatecznie reprezentowane podczas fine-tuningu, ich embeddingi mogą dryfować w kierunku pobliskich obszarów przestrzeni wektorowej, powodując międzyjęzykowe pomyłki.
Degradacja dotknęła również symbole LaTeX, znaczniki Wikipedii oraz niskiej jakości słowa kluczowe SEO, które rzadko pojawiają się w zbiorach danych do dostrajania instrukcyjnego. W istocie każdy token pozbawiony wystarczającej ekspozycji podczas post-treningu był narażony na „wyparcie” przez częściej aktualizowane tokeny.
Dlaczego post-trening stwarza ryzyko strukturalne
Przypadek ten podkreśla strukturalne napięcie w rozwoju LLM. Tokenizery są zazwyczaj budowane na podstawie dużych, zróżnicowanych korpusów wykorzystywanych w pretreningu. Jednak zbiory danych do post-treningu — zoptymalizowane pod kątem użyteczności, bezpieczeństwa i jakości dialogu — mają znacznie węższy rozkład. Gdy pokrycie tokenów staje się nierównomierne, nierównowagi statystyczne mogą kumulować się na poziomie embeddingów.
Podczas gdy zdolności rozumowania na wysokim poziomie i umiejętności konwersacyjne modelu mogą się poprawiać, jego stabilność leksykalna na niskim poziomie może stopniowo i niezauważalnie ulegać erozji. Incydent z MiniMax pokazuje, że problemy z niezawodnością mogą wynikać nie z luk w wiedzy, lecz z dryfu reprezentacji na poziomie tokenów.
Strategia naprawcza MiniMax
Aby rozwiązać problem, MiniMax wdrożył trzy działania korygujące:
- Pełne syntetyczne pokrycie słownika: Zespół wygenerował syntetyczne zadania w stylu „powtórz za mną”, aby zapewnić, że każdy token w słowniku otrzyma minimalną liczbę aktualizacji podczas post-treningu.
- Mieszanie danych z pretreningu: Części pierwotnego korpusu o szerokim pokryciu zostały włączone do etapu nadzorowanego fine-tuningu, aby przeciwdziałać zapominaniu.
- Przycinanie i monitorowanie słownika: Rzadko używane lub przestarzałe tokeny mogą zostać usunięte, a metryki pokrycia tokenów są obecnie uwzględniane w kontrolach jakości po post-treningu.
Po wprowadzeniu tych poprawek MiniMax informuje, że poziom międzyjęzykowych pomyłek w odpowiedziach japońskich spadł z 47% do 1%, a ogólna stabilność tokenów poprawiła się w całym słowniku.
Implikacje dla branży
To zdarzenie uwypukla rzadko omawiany problem niezawodności w dużych modelach językowych: pokrycie tokenów podczas post-treningu. W miarę jak modele stają się coraz bardziej wyspecjalizowane dzięki dostrajaniu instrukcyjnemu i uczeniu ze wzmocnieniem, utrzymanie równowagi statystycznej wśród setek tysięcy tokenów staje się poważnym wyzwaniem inżynieryjnym.
Dla twórców AI wniosek jest jasny: poprawa dopasowania semantycznego i wydajności zadaniowej nie może odbywać się kosztem stabilności leksykalnej. Metryki pokrycia tokenów, wykrywanie dryfu embeddingów oraz zrównoważone strategie fine-tuningu mogą stać się kluczowymi elementami przyszłych procesów oceny modeli.
To, co zaczęło się od „zapomnienia” przez model jednego imienia, ostatecznie ujawnia głębszą prawdę o dynamice treningu LLM: w wysokowymiarowych przestrzeniach wektorowych zaniedbanie długiego ogona może po cichu przekształcić fundament systemu.