OpenAI lansează benchmarkul GeneBench-Pro pentru a îmbunătăți capacitatea modelelor AI de analiză biologică
OpenAI a lansat noul benchmark GeneBench-Pro pentru a evalua capacitatea reală de cercetare a AI în sarcini biologice complexe precum genomica și proteomica. Spre deosebire de testele tradiționale, care pun accent pe memorare și fluxuri fixe, acest benchmark se concentrează mai mult pe modul în care modelele judecă, analizează și iau decizii în medii cu date haotice și incomplete.

În contextul dezvoltării rapide a biotehnologiei, modul în care pot fi analizate eficient și precis date biologice complexe a devenit o provocare importantă pentru cercetători. Pentru a îmbunătăți capacitatea practică de analiză a AI în acest domeniu, OpenAI a lansat recent noul test de referință GeneBench-Pro, axat pe evaluarea abilităților modelelor în sarcini precum genomica și proteomica, cu o atenție deosebită asupra nivelului lor de judecată și luare a deciziilor atunci când se confruntă cu date haotice și incomplete.
Diferențele esențiale față de testele de referință tradiționale
GeneBench-Pro diferă semnificativ de testele de referință tradiționale. Testele clasice pun de obicei mai mult accent pe capacitatea de memorare a modelului și pe abilitatea acestuia de a finaliza sarcinile conform unui proces prestabilit; în schimb, GeneBench-Pro pune un accent mai mare pe utilitatea modelului în medii reale de cercetare științifică.
La nivelul conceperii sarcinilor, acest benchmark introduce în mod deliberat un mediu de date „ambiguu, incomplet și cu interferențe”, cerând modelului să realizeze explorarea și analiza datelor în condiții complexe, reflectând astfel mai fidel capacitatea sa de judecată în cercetare.
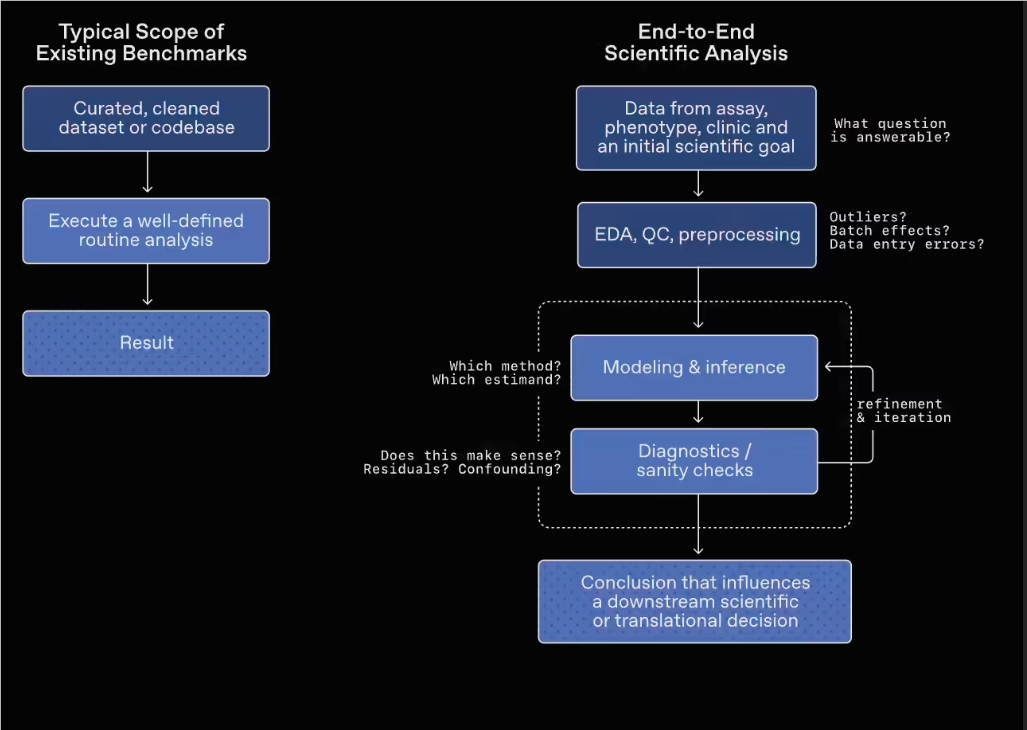
Domenii acoperite și structura întrebărilor
GeneBench-Pro acoperă mai multe direcții din biologie, inclusiv genomica, biologia cantitativă și medicina translațională, cu un total de 129 de întrebări, care vizează mai multe subdomenii:
- genetică statistică
- genetică populațională
- genomică funcțională
- proteomică
În testarea propriu-zisă, fiecare întrebare oferă modelului un set de date apropiat de mediul real de cercetare, însoțit de un scurt context experimental și de descrierea problemei. Modelul trebuie să aleagă în mod autonom metoda de analiză și să își ajusteze dinamic strategia pe baza procesului analitic, pentru a formula în final o concluzie.
Utilizarea datelor sintetice pentru reducerea erorilor de evaluare
Pentru a reduce erorile de evaluare frecvente în testele tradiționale cu fluxuri lungi de lucru, OpenAI a folosit date sintetice în conceperea GeneBench-Pro. Această abordare ajută la un control mai bun al procesului de generare a datelor, astfel încât rezultatele evaluării să reflecte mai fidel capacitatea reală a modelului de înțelegere și analiză, în loc să depindă de presupuneri sau scurtături pentru obținerea răspunsului.
Exemple deschise și planuri ulterioare de evaluare
În prezent, OpenAI a făcut publice pe platforma Hugging Face 10 exemple reprezentative GeneBench-Pro, pe care cercetătorii externi le pot explora printr-o interfață interactivă.
În plus, OpenAI intenționează să încredințeze 50 de întrebări către Artificial Analysis pentru o evaluare independentă, în vederea validării suplimentare a performanței reale a diferitelor modele în cadrul acestui benchmark.