MiniMax explică de ce modelul său M2 „a uitat” un nume: deriva tokenilor în post-antrenare
MiniMax a publicat o analiză tehnică post-incident explicând de ce modelul său M2 nu a reușit să genereze corect un anumit nume chinezesc, identificând cauza în degradarea tokenilor cu frecvență scăzută în timpul post-antrenării. Incidentul evidențiază o provocare mai amplă de fiabilitate în modelele lingvistice de mari dimensiuni: acoperirea inegală a tokenilor poate provoca o derivă structurală în spațiul de embedding, afectând nume proprii, limbi străine și simboluri rare.
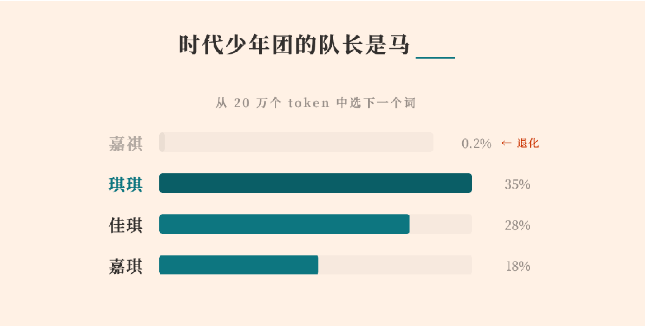
MiniMax a publicat un raport tehnic detaliat care explică de ce modelul său lingvistic de mari dimensiuni din seria M2 nu a reușit să genereze corect un anumit nume chinezesc, „马嘉祺.” Ceea ce inițial părea o eroare izolată de generare s-a transformat într-un studiu de caz revelator despre modul în care dinamica post-antrenare poate degrada în mod discret tokenii cu frecvență scăzută în modelele lingvistice mari (LLM-uri).
Cauza principală: un token „comprimat”
Potrivit MiniMax, problema a avut originea în tokenizerul modelului. Numele „马嘉祺” a fost împărțit în doi tokeni: „马” și „嘉祺.” În timpul preantrenării, „嘉祺” a apărut suficient de frecvent în datele la scară web pentru a fi combinat într-un token de sine stătător (ID 190467). Modelul a învățat reprezentarea acestuia conform așteptărilor.
Totuși, în faza ulterioară de post-antrenare—unde au loc ajustarea pe instrucțiuni și optimizarea dialogului—tokenul „嘉祺” a apărut de mai puțin de cinci ori în setul de date curatat pentru fine-tuning. Între timp, tokenii cu frecvență ridicată, legați de sintaxa codului, marcatori de invocare a uneltelor și tipare conversaționale comune, au fost consolidați în mod repetat.
Ca rezultat, embeddingul pentru tokenul cu frecvență scăzută aproape că nu a primit actualizări de gradient, în timp ce tokenii vecini, cu frecvență mare, au continuat să se deplaseze în spațiul vectorial. În timp, acest lucru a dus la ceea ce MiniMax descrie drept „derivă” sau „degenerare” a tokenului. Modelul încă păstra cunoștințe despre persoană, dar a pierdut capacitatea de a genera în mod fiabil tokenul corect, producând în schimb alternative fonetic similare.
Un tipar mai amplu: degradarea limbajului și a tokenilor din „coada lungă”
MiniMax a analizat aproximativ 200.000 de tokeni din vocabular și a constatat că aproximativ 4,9% au prezentat o degradare semnificativă după post-antrenare. Problema a fost deosebit de acută pentru tokenii japonezi, care au înregistrat o rată de degradare de 29,7%.
Aceasta ajută la explicarea unor anomalii observate anterior, cum ar fi răspunsurile în japoneză care includeau ocazional caractere rusești sau coreene. Atunci când anumiți tokeni ai unei limbi sunt subreprezentați în timpul fine-tuningului, embeddingurile lor pot deriva către regiuni apropiate din spațiul vectorial, provocând confuzie interlingvistică.
Degradarea a afectat, de asemenea, simboluri LaTeX, marcaje Wikipedia și cuvinte-cheie SEO de slabă calitate care apar rar în seturile de date pentru ajustarea pe instrucțiuni. În esență, orice token lipsit de expunere suficientă în timpul post-antrenării risca să fie „înghesuit” de tokenii actualizați mai frecvent.
De ce post-antrenarea creează un risc structural
Cazul evidențiază o tensiune structurală în dezvoltarea LLM-urilor. Tokenizerii sunt de obicei construiți pe baza unor corpuri de preantrenare vaste și diverse. Însă seturile de date pentru post-antrenare—optimizate pentru utilitate, siguranță și calitatea dialogului—au o distribuție mult mai restrânsă. Atunci când acoperirea tokenilor devine inegală, dezechilibrele statistice se pot acumula la nivelul embeddingurilor.
Deși capacitatea modelului de raționament la nivel înalt și abilitatea conversațională pot să se îmbunătățească, stabilitatea lexicală la nivel inferior se poate eroda în mod discret. Incidentul MiniMax demonstrează că problemele de fiabilitate pot apărea nu din lacune de cunoaștere, ci din deriva reprezentărilor la nivel de token.
Strategia de remediere a MiniMax
Pentru a aborda problema, MiniMax a implementat trei măsuri corective:
- Acoperire sintetică a întregului vocabular: Echipa a generat sarcini sintetice de tip „repetă după mine” pentru a se asigura că fiecare token din vocabular primește o frecvență minimă de actualizări în timpul post-antrenării.
- Combinarea datelor de preantrenare: Părți din corpusul original, cu acoperire largă, au fost integrate în etapa de fine-tuning supravegheat pentru a contracara uitarea.
- Reducerea și monitorizarea vocabularului: Tokenii rar utilizați sau depășiți pot fi eliminați, iar metricile de acoperire a tokenilor sunt acum incluse în verificările de calitate din etapa de post-antrenare.
În urma acestor remedieri, MiniMax raportează că rata confuziei interlingvistice în răspunsurile în japoneză a scăzut de la 47% la 1%, iar stabilitatea generală a tokenilor s-a îmbunătățit la nivelul întregului vocabular.
Implicații pentru industrie
Episodul evidențiază o problemă de fiabilitate insuficient discutată în cazul modelelor lingvistice mari: acoperirea tokenilor în timpul post-antrenării. Pe măsură ce modelele devin tot mai specializate prin ajustare pe instrucțiuni și învățare prin recompensă, menținerea unui echilibru statistic între sute de mii de tokeni devine o provocare inginerească deloc trivială.
Pentru dezvoltatorii de AI, concluzia este clară: îmbunătățirea alinierii semantice și a performanței pe sarcini nu poate veni în detrimentul stabilității lexicale. Metricile de acoperire a tokenilor, detectarea derivei embeddingurilor și strategiile echilibrate de fine-tuning pot deveni componente critice ale viitoarelor fluxuri de evaluare a modelelor.
Ceea ce a început ca o situație în care modelul „a uitat” un nume dezvăluie, în cele din urmă, un adevăr mai profund despre dinamica antrenării LLM-urilor: în spații vectoriale de înaltă dimensionalitate, neglijarea „cozii lungi” poate remodela în tăcere fundația sistemului.