OpenAI lancia il benchmark GeneBench-Pro, migliorando le capacità dei modelli AI nell’analisi biologica
OpenAI ha introdotto il nuovo benchmark GeneBench-Pro per valutare le reali capacità di ricerca dell’AI in compiti biologici complessi come genomica, proteomica e altri ambiti correlati. A differenza dei test tradizionali, spesso focalizzati sulla memoria e su procedure fisse, questo benchmark presta maggiore attenzione alle prestazioni dei modelli nel giudizio, nell’analisi e nel processo decisionale in contesti con dati disordinati e incompleti.

Nel contesto del rapido sviluppo delle biotecnologie, come analizzare in modo efficiente e accurato dati biologici complessi è diventato una sfida importante per i ricercatori. Per migliorare le capacità pratiche di analisi dell’AI in questo ambito, OpenAI ha recentemente pubblicato il nuovo benchmark GeneBench-Pro, progettato per valutare in particolare le capacità dei modelli in compiti di genomica, proteomica e altri ambiti correlati, con un’attenzione speciale alla qualità del giudizio e del processo decisionale di fronte a dati disordinati o incompleti.
Differenze chiave rispetto ai benchmark tradizionali
GeneBench-Pro presenta differenze evidenti rispetto ai benchmark tradizionali. I test tradizionali tendono infatti a concentrarsi maggiormente sulla capacità di memoria del modello e sulla sua abilità nel completare compiti seguendo procedure prestabilite; GeneBench-Pro, invece, pone più enfasi sulla sua utilità pratica in un contesto di ricerca reale.
Dal punto di vista della progettazione dei compiti, questo benchmark introduce volutamente ambienti di dati “ambigui, incompleti e soggetti a interferenze”, richiedendo al modello di svolgere esplorazione e analisi dei dati in condizioni complesse, così da riflettere in modo più realistico la sua capacità di giudizio nella ricerca.
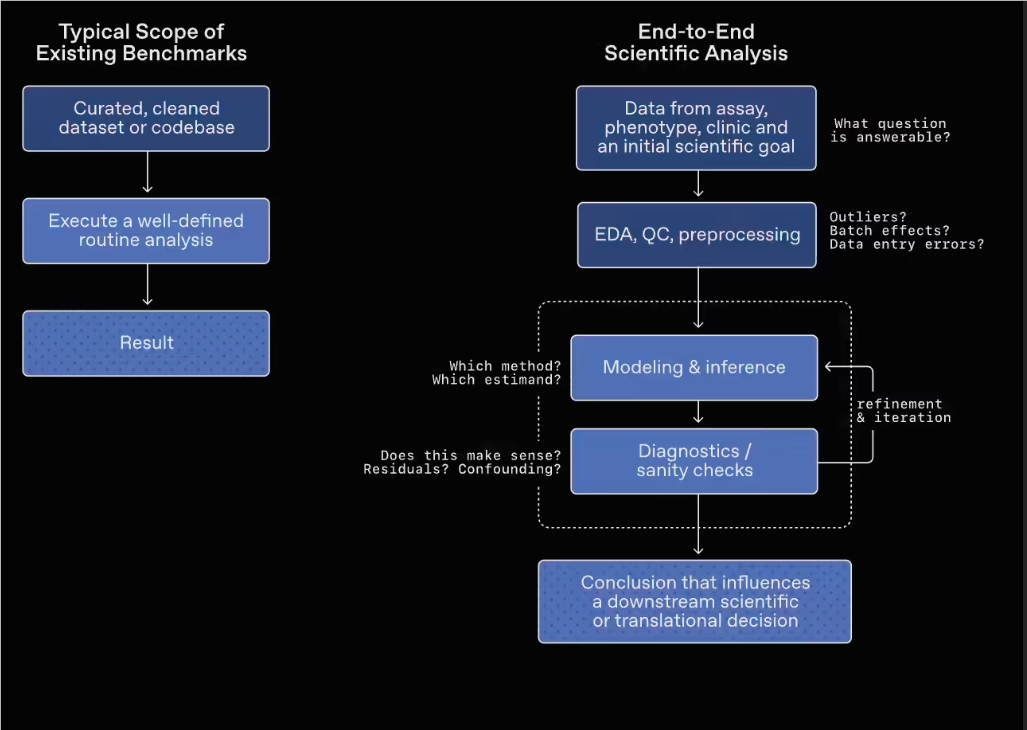
Aree coperte e struttura dei quesiti
GeneBench-Pro copre diversi ambiti della biologia, tra cui genomica, biologia quantitativa e medicina traslazionale, e include un totale di 129 quesiti, distribuiti in più sotto-discipline:
- Genetica statistica
- Genetica delle popolazioni
- Genomica funzionale
- Proteomica
Nel corso dei test, ogni quesito fornisce al modello un dataset vicino a un reale contesto di ricerca scientifica, accompagnato da un breve background sperimentale e dalla descrizione del problema. Il modello deve scegliere autonomamente i metodi di analisi e adattare dinamicamente la propria strategia in base al processo analitico, fino a formulare una conclusione finale.
Uso di dati sintetici per ridurre i bias di valutazione
Per ridurre i bias di valutazione comuni nei test tradizionali a lungo processo, OpenAI ha adottato dati sintetici nella progettazione di GeneBench-Pro. Questo approccio aiuta a controllare meglio il processo di generazione dei dati, permettendo ai risultati della valutazione di riflettere più fedelmente la reale capacità di comprensione e analisi del modello, invece di dipendere da supposizioni o scorciatoie per ottenere la risposta.
Esempi aperti e piano di valutazione successivo
Attualmente, OpenAI ha già reso open source sulla piattaforma Hugging Face 10 esempi rappresentativi di GeneBench-Pro, che i ricercatori esterni possono provare tramite un’interfaccia interattiva.
Inoltre, OpenAI prevede di affidare 50 quesiti ad Artificial Analysis per una valutazione indipendente, al fine di verificare ulteriormente le prestazioni effettive dei diversi modelli su questo benchmark.