OpenAI publie le benchmark GeneBench-Pro pour améliorer les capacités d’analyse biologique des modèles d’IA
OpenAI a lancé le tout nouveau benchmark GeneBench-Pro afin d’évaluer les capacités réelles de recherche de l’IA dans des tâches biologiques complexes telles que la génomique et la protéomique. Contrairement aux tests traditionnels, davantage axés sur la mémorisation et des processus fixes, ce benchmark met davantage l’accent sur les performances des modèles en matière de jugement, d’analyse et de prise de décision dans des environnements de données désordonnés et incomplets.

Dans le contexte du développement rapide des biotechnologies, la manière d’analyser efficacement et avec précision des données biologiques complexes est devenue un défi majeur pour les chercheurs. Afin d’améliorer les capacités d’analyse concrètes de l’IA dans ce domaine, OpenAI a récemment publié un tout nouveau benchmark, GeneBench-Pro, visant à évaluer en priorité les compétences des modèles dans des tâches liées à la génomique, à la protéomique et à d’autres disciplines, avec une attention particulière portée à leur jugement et à leur prise de décision face à des données désordonnées ou incomplètes.
Différences essentielles avec les benchmarks traditionnels
GeneBench-Pro se distingue nettement des benchmarks traditionnels. Les tests classiques mettent généralement davantage l’accent sur la capacité de mémorisation du modèle, ainsi que sur son aptitude à accomplir une tâche en suivant un processus prédéfini ; à l’inverse, GeneBench-Pro insiste davantage sur l’utilité réelle du modèle dans un environnement de recherche scientifique.
Dans la conception des tâches, ce benchmark introduit délibérément un environnement de données « floues, incomplètes et perturbées », exigeant du modèle qu’il mène l’exploration et l’analyse des données dans des conditions complexes, afin de refléter plus fidèlement sa capacité de jugement scientifique.
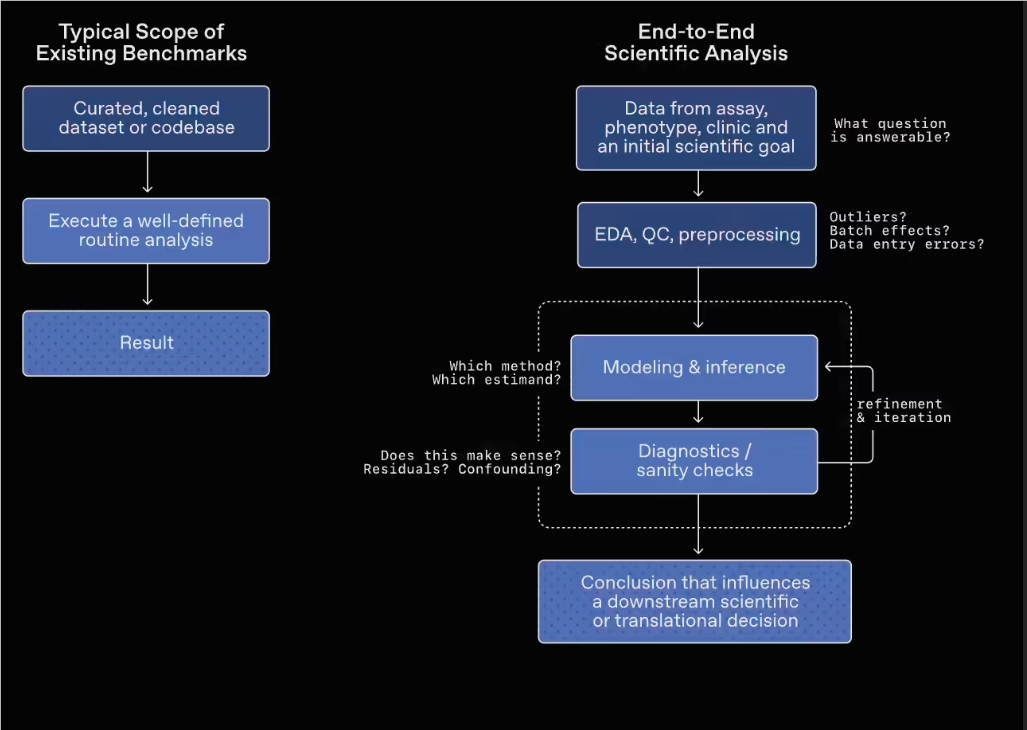
Domaines couverts et configuration des questions
GeneBench-Pro couvre plusieurs domaines de la biologie, notamment la génomique, la biologie quantitative et la médecine translationnelle, avec un total de 129 questions réparties dans plusieurs sous-domaines :
- Génétique statistique
- Génétique des populations
- Génomique fonctionnelle
- Protéomique
Dans les tests concrets, chaque question fournit au modèle un jeu de données proche des conditions réelles de la recherche scientifique, accompagné d’un bref contexte expérimental et d’une description du problème. Le modèle doit choisir lui-même sa méthode d’analyse, ajuster dynamiquement sa stratégie au fil du processus analytique, puis formuler une conclusion finale.
Utilisation de données synthétiques pour réduire les biais d’évaluation
Afin de limiter les biais d’évaluation fréquemment observés dans les tests traditionnels à long déroulement, OpenAI a recours à des données synthétiques dans la conception de GeneBench-Pro. Cette approche permet de mieux contrôler le processus de génération des données, de sorte que les résultats de l’évaluation reflètent davantage la véritable capacité de compréhension et d’analyse du modèle, plutôt que sa faculté à deviner ou à trouver des raccourcis pour obtenir la réponse.
Exemples ouverts et plan d’évaluation à venir
À l’heure actuelle, OpenAI a déjà publié en open source sur la plateforme Hugging Face 10 exemples représentatifs de GeneBench-Pro, que les chercheurs externes peuvent tester via une interface interactive.
Par ailleurs, OpenAI prévoit également de confier 50 questions à Artificial Analysis pour une évaluation indépendante, afin de vérifier plus avant les performances réelles des différents modèles sur ce benchmark.