MiniMax explique pourquoi son modèle M2 a « oublié » un nom : dérive des tokens après le post-entraînement
MiniMax a publié une analyse technique détaillant pourquoi son modèle M2 n’a pas réussi à générer correctement un nom chinois spécifique, attribuant le problème à la dégradation des tokens à faible fréquence lors du post-entraînement. Cet incident met en lumière un défi plus large de fiabilité des grands modèles de langage : une couverture inégale des tokens peut provoquer une dérive structurelle dans l’espace d’embedding, affectant les noms, les langues étrangères et les symboles rares.
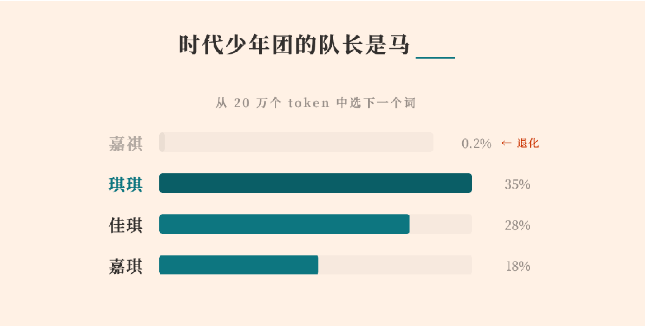
MiniMax a publié un rapport technique détaillé expliquant pourquoi son modèle de langage de grande taille de la série M2 n’a pas pu générer correctement un nom chinois spécifique, « 马嘉祺 ». Ce qui semblait au départ être un simple problème isolé de génération s’est transformé en une étude de cas révélatrice sur la manière dont les dynamiques de post-entraînement peuvent discrètement dégrader les tokens à faible fréquence dans les grands modèles de langage (LLM).
La cause profonde : un token « comprimé »
Selon MiniMax, le problème provient du tokenizer du modèle. Le nom « 马嘉祺 » a été divisé en deux tokens : « 马 » et « 嘉祺 ». Lors du préentraînement, « 嘉祺 » apparaissait suffisamment fréquemment dans les données à l’échelle du web pour être fusionné en un token autonome (ID 190467). Le modèle a appris sa représentation comme prévu.
Cependant, lors de la phase ultérieure de post-entraînement — où ont lieu l’ajustement par instructions et l’optimisation du dialogue — le token « 嘉祺 » est apparu moins de cinq fois dans le jeu de données de fine-tuning soigneusement sélectionné. Pendant ce temps, des tokens à haute fréquence liés à la syntaxe du code, aux marqueurs d’invocation d’outils et aux schémas conversationnels courants ont été renforcés à plusieurs reprises.
En conséquence, l’embedding du token à faible fréquence n’a presque reçu aucune mise à jour par gradient, tandis que les tokens voisins à haute fréquence continuaient de se déplacer dans l’espace vectoriel. Au fil du temps, cela a conduit à ce que MiniMax décrit comme une « dérive » ou une « dégénérescence » du token. Le modèle conservait toujours des connaissances sur la personne, mais il a perdu la capacité de générer de manière fiable le token correct, produisant à la place des alternatives phonétiquement similaires.
Un schéma plus large : langue et dégradation des tokens de longue traîne
MiniMax a analysé environ 200 000 tokens du vocabulaire et a constaté qu’environ 4,9 % présentaient une dégradation significative après le post-entraînement. Le problème était particulièrement aigu pour les tokens japonais, qui affichaient un taux de dégradation de 29,7 %.
Cela permet d’expliquer des anomalies précédemment observées, telles que des réponses en japonais mélangeant occasionnellement des caractères russes ou coréens. Lorsque certains tokens linguistiques sont sous-représentés lors du fine-tuning, leurs embeddings peuvent dériver vers des régions voisines dans l’espace vectoriel, provoquant une confusion interlinguistique.
La dégradation a également affecté les symboles LaTeX, le balisage Wikipédia et les mots-clés SEO de faible qualité qui apparaissent rarement dans les jeux de données d’ajustement par instructions. En substance, tout token ne bénéficiant pas d’une exposition suffisante pendant le post-entraînement risquait d’être « évincé » par des tokens mis à jour plus fréquemment.
Pourquoi le post-entraînement crée un risque structurel
Ce cas met en lumière une tension structurelle dans le développement des LLM. Les tokenizers sont généralement construits à partir de vastes corpus de préentraînement diversifiés. Mais les jeux de données de post-entraînement — optimisés pour l’utilité, la sécurité et la qualité du dialogue — sont beaucoup plus restreints en termes de distribution. Lorsque la couverture des tokens devient inégale, des déséquilibres statistiques peuvent s’accumuler au niveau des embeddings.
Si les capacités de raisonnement de haut niveau et de conversation du modèle peuvent s’améliorer, sa stabilité lexicale de bas niveau peut s’éroder discrètement. L’incident MiniMax démontre que des problèmes de fiabilité peuvent émerger non pas d’un manque de connaissances, mais d’une dérive représentationnelle au niveau des tokens.
La stratégie d’atténuation de MiniMax
Pour résoudre le problème, MiniMax a mis en œuvre trois mesures correctives :
- Couverture synthétique du vocabulaire complet : L’équipe a généré des tâches synthétiques de type « répète après moi » afin de garantir que chaque token du vocabulaire reçoive une fréquence minimale de mises à jour pendant le post-entraînement.
- Intégration de données de préentraînement : Des portions du corpus original à large couverture ont été mélangées à l’étape de fine-tuning supervisé afin de contrer l’oubli.
- Élagage et surveillance du vocabulaire : Les tokens rarement utilisés ou obsolètes peuvent être supprimés, et des métriques de couverture des tokens sont désormais incluses dans les contrôles de qualité du post-entraînement.
À la suite de ces corrections, MiniMax rapporte que la confusion interlinguistique dans les réponses en japonais est passée de 47 % à 1 %, et que la stabilité globale des tokens s’est améliorée dans l’ensemble du vocabulaire.
Implications pour l’industrie
Cet épisode met en évidence un problème de fiabilité peu discuté dans les grands modèles de langage : la couverture au niveau des tokens pendant le post-entraînement. À mesure que les modèles deviennent de plus en plus spécialisés grâce à l’ajustement par instructions et à l’apprentissage par renforcement, maintenir un équilibre statistique à travers des centaines de milliers de tokens devient un défi d’ingénierie non trivial.
Pour les développeurs d’IA, la conclusion est claire : améliorer l’alignement sémantique et les performances sur les tâches ne peut se faire au détriment de la stabilité lexicale. Les métriques de couverture des tokens, la détection de dérive des embeddings et les stratégies de fine-tuning équilibrées pourraient devenir des composantes essentielles des futurs processus d’évaluation des modèles.
Ce qui a commencé par un modèle « oubliant » un nom révèle finalement une vérité plus profonde sur les dynamiques d’entraînement des LLM : dans des espaces vectoriels de haute dimension, négliger la longue traîne peut silencieusement remodeler les fondations du système.