OpenAI veröffentlicht den Benchmark GeneBench-Pro und verbessert die biologischen Analysefähigkeiten von KI-Modellen
OpenAI hat den neuen Benchmark GeneBench-Pro eingeführt, um die tatsächlichen Forschungsfähigkeiten von KI bei komplexen biologischen Aufgaben in Bereichen wie Genomik und Proteomik zu bewerten. Im Gegensatz zu herkömmlichen Tests, die stärker auf Gedächtnisleistung und feste Abläufe ausgerichtet sind, konzentriert sich dieser Benchmark stärker auf das Urteilsvermögen, die Analyse und die Entscheidungsfindung von Modellen in chaotischen und unvollständigen Datenumgebungen.

Vor dem Hintergrund der rasanten Entwicklung der Biotechnologie ist die Frage, wie komplexe biologische Daten effizient und präzise analysiert werden können, zu einer wichtigen Herausforderung für Forschende geworden. Um die praktische Analysefähigkeit von KI in diesem Bereich zu verbessern, hat OpenAI kürzlich den neuen Benchmark GeneBench-Pro veröffentlicht, der die Forschungsfähigkeit von Modellen bei Aufgaben in der Genomik, Proteomik und weiteren Bereichen gezielt bewertet und dabei besonders auf ihr Urteils- und Entscheidungsvermögen beim Umgang mit chaotischen und unvollständigen Daten achtet.
Der zentrale Unterschied zu traditionellen Benchmarks
GeneBench-Pro unterscheidet sich deutlich von traditionellen Benchmarks. Herkömmliche Tests legen meist mehr Wert auf das Erinnerungsvermögen von Modellen und darauf, ob sie Aufgaben nach einem vorgegebenen Ablauf ausführen können; GeneBench-Pro hingegen betont stärker die praktische Nutzbarkeit von Modellen in realen wissenschaftlichen Umgebungen.
Beim Aufgabendesign führt dieser Benchmark absichtlich eine Datenumgebung ein, die „mehrdeutig, unvollständig und störbehaftet“ ist, und verlangt von den Modellen, unter komplexen Bedingungen Daten zu erkunden und zu analysieren, um ihre Fähigkeit zu wissenschaftlicher Urteilsbildung realistischer abzubilden.
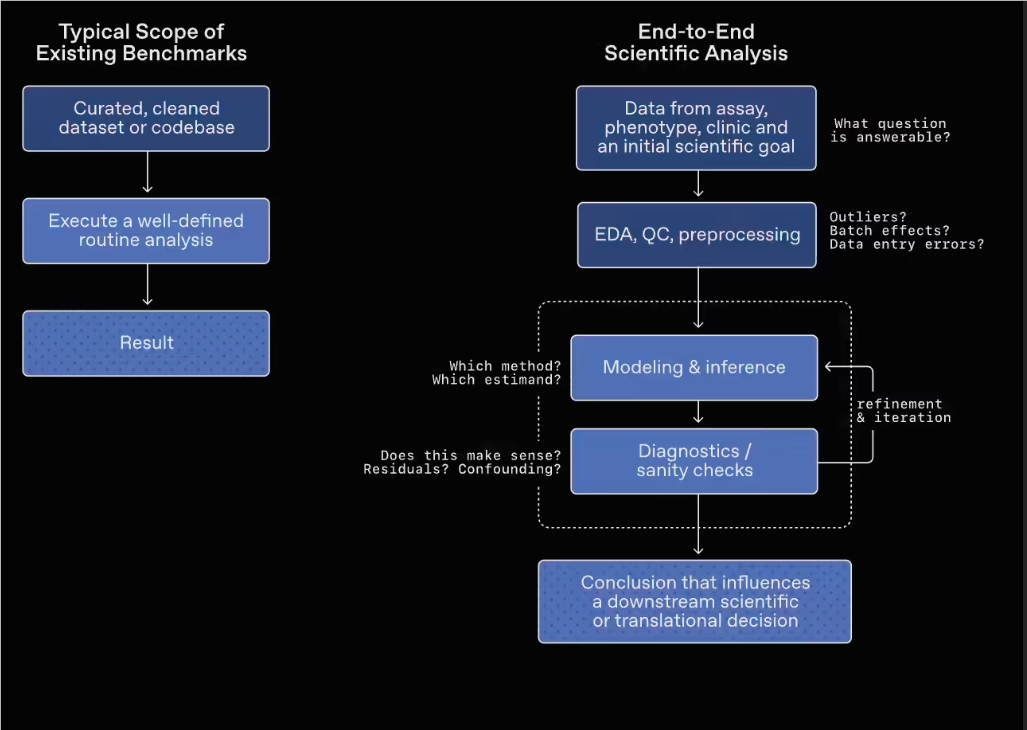
Abgedeckte Bereiche und Aufgabenstellung
GeneBench-Pro deckt mehrere biologische Fachrichtungen ab, darunter Genomik, quantitative Biologie und translationale Medizin. Insgesamt umfasst der Benchmark 129 Aufgaben und mehrere Teilgebiete:
- Statistische Genetik
- Populationsgenetik
- Funktionelle Genomik
- Proteomik
In den konkreten Tests erhält das Modell für jede Aufgabe einen Datensatz, der realen Forschungsumgebungen nahekommt, ergänzt durch einen kurzen experimentellen Hintergrund und eine Problembeschreibung. Das Modell muss die Analysemethode selbstständig auswählen, seine Strategie im Verlauf der Analyse dynamisch anpassen und schließlich eine Schlussfolgerung liefern.
Einsatz synthetischer Daten zur Verringerung von Bewertungsverzerrungen
Um die in traditionellen Tests mit langen Prozessketten häufig auftretenden Bewertungsverzerrungen zu reduzieren, verwendet OpenAI im Design von GeneBench-Pro synthetische Daten. Dies hilft dabei, den Datengenerierungsprozess besser zu kontrollieren, sodass die Bewertungsergebnisse die tatsächlichen Fähigkeiten der Modelle in Verständnis und Analyse besser widerspiegeln, anstatt dass Antworten durch Raten oder Abkürzungen erzielt werden.
Offene Beispiele und weitere Evaluierungspläne
Derzeit hat OpenAI auf der Plattform Hugging Face 10 repräsentative Beispielaufgaben von GeneBench-Pro als Open Source veröffentlicht, die externe Forschende über eine interaktive Oberfläche ausprobieren können.
Darüber hinaus plant OpenAI, 50 Aufgaben davon von Artificial Analysis unabhängig evaluieren zu lassen, um die tatsächliche Leistung unterschiedlicher Modelle in diesem Benchmark weiter zu überprüfen.