MiniMax erklärt, warum sein M2-Modell einen Namen ‚vergaß‘: Token-Drift im Post-Training
MiniMax hat eine technische Post-Mortem-Analyse veröffentlicht, die erklärt, warum sein M2-Modell einen bestimmten chinesischen Namen nicht korrekt generieren konnte. Als Ursache wurde die Degradation von Tokens mit niedriger Frequenz während des Post-Trainings identifiziert. Der Vorfall verdeutlicht eine grundlegende Zuverlässigkeitsherausforderung großer Sprachmodelle: Eine ungleichmäßige Token-Abdeckung kann zu struktureller Drift im Embedding-Raum führen und Namen, Fremdsprachen sowie selten
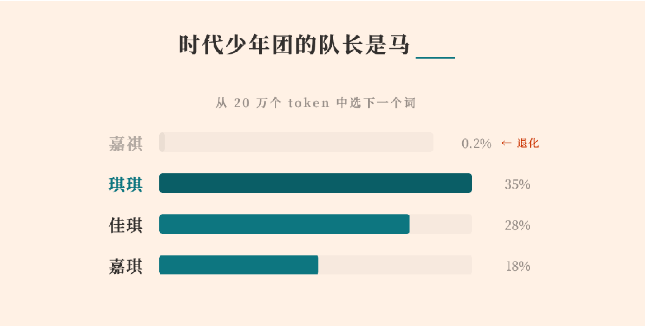
MiniMax hat einen ausführlichen technischen Bericht veröffentlicht, in dem erklärt wird, warum sein Large-Language-Model der M2-Serie nicht in der Lage war, einen bestimmten chinesischen Namen „马嘉祺“ korrekt zu generieren. Was zunächst wie ein isolierter Ausgabefehler erschien, entwickelte sich zu einer aufschlussreichen Fallstudie darüber, wie Post-Training-Dynamiken seltene Tokens in großen Sprachmodellen (LLMs) unbemerkt beeinträchtigen können.
Die Ursache: Ein „zusammengedrücktes“ Token
Laut MiniMax lag der Ursprung des Problems im Tokenizer des Modells. Der Name „马嘉祺“ wurde in zwei Tokens aufgeteilt: „马“ und „嘉祺“. Während des Pretrainings kam „嘉祺“ in Web-Daten in ausreichender Häufigkeit vor, um als eigenständiges Token (ID 190467) zusammengeführt zu werden. Das Modell lernte seine Repräsentation wie erwartet.
In der späteren Post-Training-Phase – in der Instruction-Tuning und Dialogoptimierung stattfinden – erschien das Token „嘉祺“ jedoch weniger als fünfmal im kuratierten Fine-Tuning-Datensatz. Gleichzeitig wurden hochfrequente Tokens im Zusammenhang mit Codesyntax, Tool-Aufruf-Markern und gängigen Gesprächsmustern wiederholt verstärkt.
Infolgedessen erhielt das Embedding des seltenen Tokens nahezu keine Gradienten-Updates, während sich benachbarte hochfrequente Tokens im Vektorraum weiter verschoben. Im Laufe der Zeit führte dies zu dem, was MiniMax als Token-„Drift“ oder „Degeneration“ beschreibt. Das Modell behielt zwar das Wissen über die Person, verlor jedoch die Fähigkeit, das korrekte Token zuverlässig zu erzeugen, und produzierte stattdessen phonetisch ähnliche Alternativen.
Ein breiteres Muster: Sprach- und Long-Tail-Token-Degradation
MiniMax analysierte rund 200.000 Vokabular-Tokens und stellte fest, dass etwa 4,9 % nach dem Post-Training eine signifikante Degradation aufwiesen. Besonders ausgeprägt war das Problem bei japanischen Tokens, die eine Degradationsrate von 29,7 % zeigten.
Dies erklärt zuvor beobachtete Anomalien, etwa dass japanische Antworten gelegentlich russische oder koreanische Zeichen enthielten. Wenn bestimmte Sprach-Tokens während des Fine-Tunings unterrepräsentiert sind, können ihre Embeddings in benachbarte Regionen des Vektorraums abdriften, was zu sprachübergreifender Verwechslung führt.
Die Degradation betraf auch LaTeX-Symbole, Wikipedia-Markup und minderwertige SEO-Schlüsselwörter, die in Instruction-Tuning-Datensätzen selten vorkommen. Im Wesentlichen war jedes Token, das während des Post-Trainings nicht ausreichend berücksichtigt wurde, dem Risiko ausgesetzt, von häufiger aktualisierten Tokens „verdrängt“ zu werden.
Warum Post-Training ein strukturelles Risiko schafft
Der Fall unterstreicht eine strukturelle Spannung in der Entwicklung von LLMs. Tokenizer werden in der Regel aus großen, vielfältigen Pretraining-Korpora aufgebaut. Post-Training-Datensätze – optimiert für Nützlichkeit, Sicherheit und Dialogqualität – sind jedoch in ihrer Verteilung deutlich enger gefasst. Wenn die Abdeckung der Tokens unausgewogen wird, können sich statistische Ungleichgewichte auf Embedding-Ebene ansammeln.
Während sich die hochrangigen Fähigkeiten des Modells in Bezug auf Schlussfolgern und Konversation verbessern, kann seine lexikalische Stabilität auf niedriger Ebene unbemerkt erodieren. Der Vorfall bei MiniMax zeigt, dass Zuverlässigkeitsprobleme nicht nur aus Wissenslücken entstehen können, sondern auch aus Repräsentationsdrift auf Token-Ebene.
Die Gegenmaßnahmen von MiniMax
Um das Problem zu beheben, implementierte MiniMax drei Korrekturmaßnahmen:
- Synthetische Vollabdeckung des Vokabulars: Das Team generierte synthetische „Wiederhole-nach-mir“-Aufgaben, um sicherzustellen, dass jedes Token im Vokabular während des Post-Trainings eine Mindestanzahl an Updates erhält.
- Beimischung von Pretraining-Daten: Teile des ursprünglichen, breit gefächerten Korpus wurden in die Phase des überwachten Fine-Tunings integriert, um dem Vergessen entgegenzuwirken.
- Bereinigung und Überwachung des Vokabulars: Selten verwendete oder veraltete Tokens können entfernt werden, und Metriken zur Token-Abdeckung sind nun Bestandteil der Qualitätskontrollen im Post-Training.
Nach diesen Maßnahmen berichtet MiniMax, dass die sprachübergreifende Verwechslung in japanischen Ausgaben von 47 % auf 1 % gesunken ist und sich die Token-Stabilität im gesamten Vokabular insgesamt verbessert hat.
Implikationen für die Branche
Der Vorfall verdeutlicht ein bislang wenig diskutiertes Zuverlässigkeitsproblem bei großen Sprachmodellen: die Token-Abdeckung während des Post-Trainings. Da Modelle durch Instruction-Tuning und Reinforcement Learning zunehmend spezialisiert werden, wird es zu einer nicht trivialen ingenieurtechnischen Herausforderung, die statistische Balance über Hunderttausende von Tokens hinweg aufrechtzuerhalten.
Für KI-Entwickler ist die Schlussfolgerung klar: Die Verbesserung semantischer Ausrichtung und Aufgabenleistung darf nicht auf Kosten der lexikalischen Stabilität gehen. Metriken zur Token-Abdeckung, die Erkennung von Embedding-Drift und ausgewogene Fine-Tuning-Strategien könnten zu zentralen Bestandteilen zukünftiger Modellbewertungspipelines werden.
Was damit begann, dass ein Modell einen Namen „vergaß“, offenbart letztlich eine tiefere Wahrheit über die Trainingsdynamik von LLMs: In hochdimensionalen Vektorräumen kann die Vernachlässigung des Long Tails still und leise das Fundament des Systems verändern.