OpenAI Launches GeneBench-Pro to Boost AI's Biological Analysis Capabilities
OpenAI has introduced GeneBench-Pro, a cutting-edge benchmark designed to evaluate AI’s real-world research capabilities in complex biological tasks such as genomics and proteomics. Unlike traditional testing methods that rely heavily on rote memorization and fixed protocols, this new benchmark shifts the focus to how effectively models can judge, analyze, and make critical decisions when navigating chaotic and incomplete data environments.

Against the backdrop of rapidly advancing biotechnology, efficiently and accurately analyzing intricate biological data has become a critical bottleneck for researchers. To elevate AI’s real-world analytical proficiency in this domain, OpenAI recently unveiled GeneBench-Pro. This brand-new benchmark is purpose-built to evaluate a model's practical research capabilities in fields like genomics and proteomics, placing a sharp focus on its judgment and decision-making skills when confronted with chaotic or fragmented data.
Core Distinctions: GeneBench-Pro vs. Traditional Benchmarks
GeneBench-Pro marks a radical departure from traditional benchmarking methods. While legacy evaluations predominantly measure a model’s factual retention and its ability to follow rigid, pre-defined protocols, GeneBench-Pro places its bets on real-world scientific utility.
Rather than spoon-feeding AI models pristine datasets, this benchmark deliberately engineer task environments with ambiguous, fragmented, and noisy data. By forcing models to navigate data exploration and analysis under these volatile conditions, it provides a much more authentic reflection of their genuine research acumen and analytical judgment.
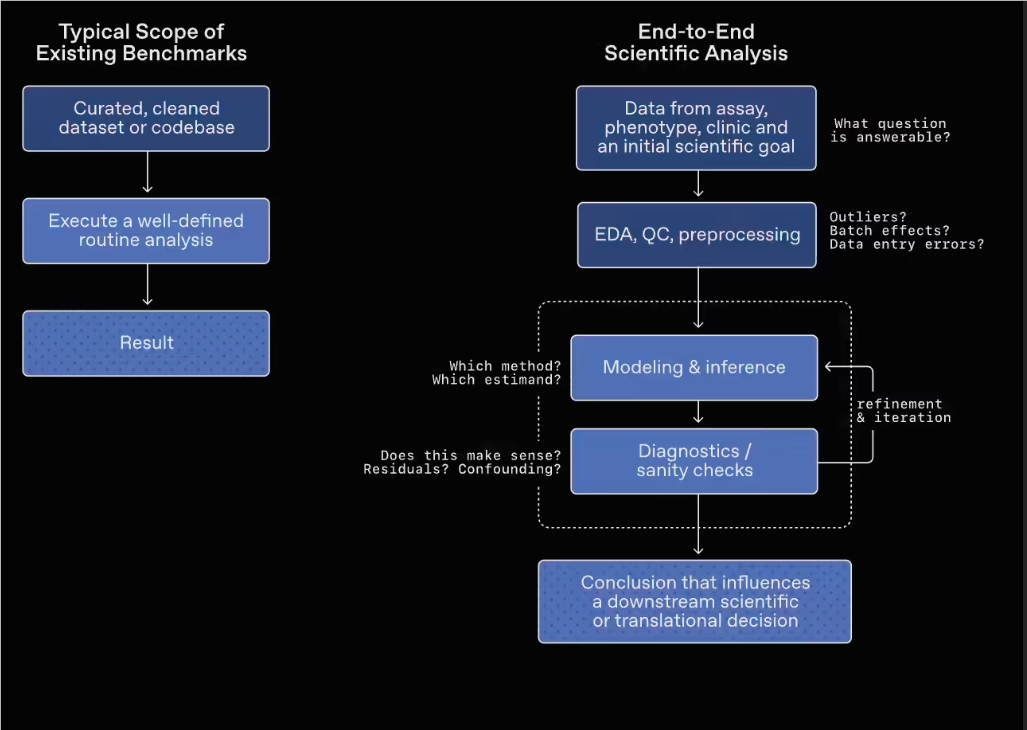
Evaluated Domains & Task Architecture
GeneBench-Pro spans multiple pivotal biological disciplines, including genomics, quantitative biology, and translational medicine. The benchmark features a total of 129 specialized problems distributed across key subfields, such as:
Statistical Genetics
Population Genetics
Functional Genomics
Proteomics
Within the practical evaluation, each problem equips the AI model with a dataset that mirrors live, raw research environments, paired with a concise experimental background and problem description. Rather than following a rigid script, the model must autonomously determine the optimal analytical methodology, dynamically pivot its strategy based on unfolding insights, and synthesize the final scientific conclusion.
Utilizing Synthetic Data to Mitigate Rating Bias
To minimize the rating biases that commonly plague traditional, multi-step benchmarks, OpenAI integrated synthetic data into GeneBench-Pro's core architecture. This methodological shift allows for tighter control over the data generation pipeline. Consequently, the scoring reflects a model's true comprehension and analytical depth, preventing it from gaming the test through lucky guesses or heuristic shortcuts.
Open-Source Examples & The Roadmap Ahead
Currently, OpenAI has open-sourced 10 representative GeneBench-Pro sample problems on the Hugging Face platform, allowing external researchers to get hands-on experience through an interactive interface.
Looking ahead, OpenAI plans to hand over a subset of 50 problems to Artificial Analysis for independent evaluation. This upcoming third-party testing aims to further validate and cross-examine the real-world performance of various AI models against this new benchmark.