MiniMax Explains Why Its M2 Model ‘Forgot’ a Name: Token Drift in Post-Training
MiniMax has published a technical postmortem explaining why its M2 model failed to correctly generate a specific Chinese name, tracing the issue to low-frequency token degradation during post-training. The incident highlights a broader reliability challenge in large language models: uneven token coverage can cause structural drift in the embedding space, affecting names, foreign languages, and rare symbols.
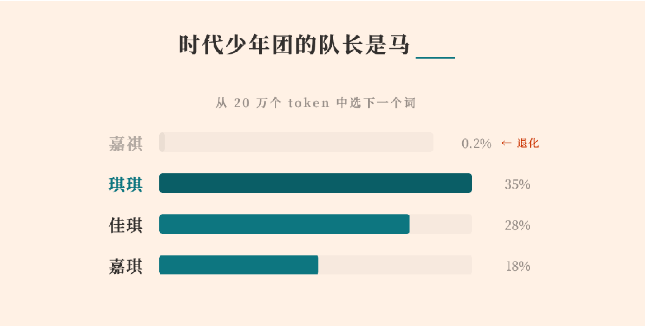
MiniMax has released a detailed technical report explaining why its M2 series large language model was unable to correctly generate a specific Chinese name, “马嘉祺.” What initially appeared to be an isolated output glitch has turned into a revealing case study on how post-training dynamics can quietly degrade low-frequency tokens in large language models (LLMs).
The Root Cause: A “Squeezed” Token
According to MiniMax, the issue originated in the model’s tokenizer. The name “马嘉祺” was split into two tokens: “马” and “嘉祺.” During pretraining, “嘉祺” appeared frequently enough in web-scale data to be merged into a standalone token (ID 190467). The model learned its representation as expected.
However, in the later post-training phase—where instruction tuning and dialogue optimization occur—the token “嘉祺” appeared fewer than five times in the curated fine-tuning dataset. Meanwhile, high-frequency tokens related to code syntax, tool invocation markers, and common conversational patterns were repeatedly reinforced.
As a result, the embedding for the low-frequency token received almost no gradient updates, while neighboring high-frequency tokens continued shifting in vector space. Over time, this led to what MiniMax describes as token “drift” or “degeneration.” The model still retained knowledge about the person, but it lost the ability to reliably generate the correct token, instead producing phonetically similar alternatives.
A Broader Pattern: Language and Long-Tail Token Degradation
MiniMax conducted a scan of roughly 200,000 vocabulary tokens and found that approximately 4.9% showed significant degradation after post-training. The problem was particularly acute for Japanese tokens, which exhibited a 29.7% degradation rate.
This helps explain previously observed anomalies, such as Japanese responses occasionally mixing in Russian or Korean characters. When certain language tokens are underrepresented during fine-tuning, their embeddings may drift toward nearby regions in vector space, causing cross-lingual confusion.
The degradation also affected LaTeX symbols, Wikipedia markup, and low-quality SEO keywords that rarely appear in instruction-tuning datasets. In essence, any token lacking sufficient exposure during post-training risked being “crowded out” by more frequently updated tokens.
Why Post-Training Creates Structural Risk
The case underscores a structural tension in LLM development. Tokenizers are typically built from large, diverse pretraining corpora. But post-training datasets—optimized for helpfulness, safety, and dialogue quality—are much narrower in distribution. When coverage across tokens becomes uneven, statistical imbalances can accumulate at the embedding level.
While the model’s high-level reasoning and conversational ability may improve, its low-level lexical stability can quietly erode. The MiniMax incident demonstrates that reliability challenges can emerge not from knowledge gaps, but from representational drift at the token level.
MiniMax’s Mitigation Strategy
To address the issue, MiniMax implemented three corrective measures:
- Full-vocabulary synthetic coverage: The team generated synthetic “repeat-after-me” style tasks to ensure every token in the vocabulary receives a minimum frequency of updates during post-training.
- Blending pretraining data: Portions of the original broad-coverage corpus were mixed into the supervised fine-tuning stage to counteract forgetting.
- Vocabulary pruning and monitoring: Rarely used or obsolete tokens may be removed, and token coverage metrics are now included in post-training quality checks.
Following these fixes, MiniMax reports that cross-language confusion in Japanese outputs dropped from 47% to 1%, and overall token stability improved across the vocabulary.
Industry Implications
The episode highlights an under-discussed reliability issue in large language models: token-level coverage during post-training. As models become increasingly specialized through instruction tuning and reinforcement learning, maintaining statistical balance across hundreds of thousands of tokens becomes a non-trivial engineering challenge.
For AI developers, the takeaway is clear: improving semantic alignment and task performance cannot come at the expense of lexical stability. Token coverage metrics, embedding drift detection, and balanced fine-tuning strategies may become critical components of future model evaluation pipelines.
What began as a model “forgetting” a name ultimately reveals a deeper truth about LLM training dynamics: in high-dimensional vector spaces, neglecting the long tail can quietly reshape the foundation of the system.